Simulation Meta Data🔗
It is the meta data that allows objects, like data sets and model setups to be findable by both humans and machines. They are therefore an essential part of a simulation package that is going to be published or shared with others for further development.
However, the compilation of the meta data can be a bold venture: on the one hand it is extremely useful to have every tiny detail to look for. On the other hand the user has to provide all the information in the first place which costs time, especially if the meta data requires a lots of tweaking and transformation. Which rises immediately the question
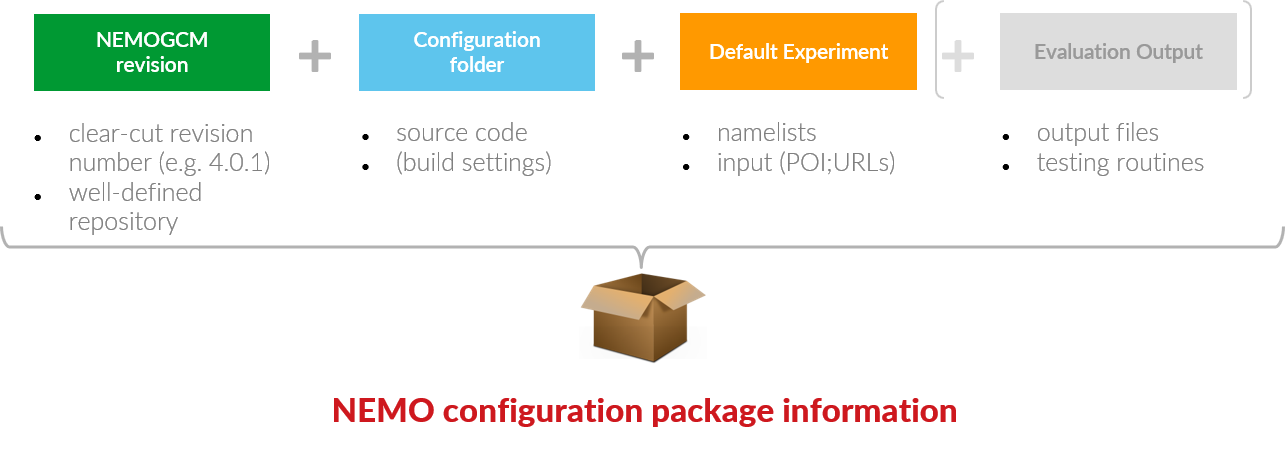
Before answering this question, we need to know the overall extent and the major components of the sharable object, the "Simulation Package".
The Simulation Package🔗
The Simulation Package comprises the aforementioned components:
-
The source code (code base and user modifications)
-
The setting and environment for the build process (model conponents, macros and compiler choices)
-
The run-time environment for a specific simulation (parameters and input)
-
Control output for evaluation
1. Source Code🔗
The code base, a simulation is build from, must be unequivocally identifiable, i.e. the code must be version controlled and the exact revision must be known. NEMO uses Subversion as a version control system. Changes are tracked on the server globally and each modification (commit) is associated with a globel changeset/revision number. This can lead to situations where two checkouts represent the exact same code although the revision numbers are different. But together with the directory structure for the different development and release branches the code base for a specific simulation can be sufficently characterized and referenced.
Code modifications and extensions on top for a simulation must be be tracked and controlled by the user. Refering to a private repository (svn or git) however might not be sufficient and implicates some risk regarding mid- and long-term documentation. This part of the code should be therefore included in the package.
2. Build Environment🔗
Beside the code base and the code modifications by the user, the build environment is another essential module in order to sustain a reproducible simulation development. It must be documented, which components of the code have been included (model components) and whether and how macro definitions (CPP Keys) for masking the code were involved. Furthermore, the manufacturer and the version of the compiler itself as well as the options and arguments of the compiler command must be put on record.
3. Run-time Environment🔗
Even with the same executable, complete different simulations can be achieved by slightly changing only a few parameters, boundary conditions or the initial state. While the run-time parameters (FORTRAN namelists) can be easily documented (they could be even transferred to some Database), input files have been neglected somehow. These data files are often hard to handle due to the size of a single file or a voluminous data collection. The size is also often the reason why there is no version control of such files and modifications are not tracked. Unfortunately, this compromises every effort to perform reproducible simulations and thus obstructs comprehensible research.
SIMSAR provides a strategy how to overcome this huddle as laid out in the section Citable Input Data. For that purpose, the Simulation Package will contain a file (input.ini) which lists all necessary input data files each with an entry how to obtain the data and with the option to attach references, citations and a checksums. This is not a description of the input data as extensive as it is propsed for instance by the DataCite Metadata Schema, but it provides a first partial compliance with modern data management.
Special attention should be also payed to the setup which defines the output data written during the run. Not only does this permit the experienced user to learn about what to expect from the output. But the user can also find more information about the structure of the output data if questions or uncertainties emerge during the analysis of the output.
4. Evaluation🔗
Part of the reproduction of a simulation is some check if the new output matches the results from the original simulation. Therefore, graphics and data fields from the original run are needed and should be attached to the Simulation Package (e.g. simple timeseries of indices or similar) while volumetric and/or raw data could be referenced using a persistent identifier (PID) for the published output data set.
Assemble the Meta-Data🔗
In response to the question in the first paragraph, here is an overview of the meta-data you're going to assemble with SIMSAR:
| Pos. | Scope | Meta-Data | Procedure |
|---|---|---|---|
| 1 | source code | Repository, Branch, Revision, User Contact, | README, git repo |
| 2 | build environment | Model Components, CPP Keys, ~~Compiler Info~~ (future version) | README |
| 3 | run-time environment | FORTRAN namelists, XIOS XML, | README, EXP folder |
| 4 | evaluation data | graphics, time series, 2D fields | DIAGS/ |
Mot of the meta-data can be gathered using the mkReadme script provided by SIMSAR. This script is run in the experiment folder and expects little input from the user while the majority is retrieved automatically. See the section Create the README file with mkReadme for instructions how to invoke the script or click on the button below.